Assignment #5 - Cats Photo Editing
Background
In this assignment, I will implement a few different techniques for manipulating images on the manifold of natural images.
First, I will invert a pre-trained generator to find a latent variable that closely reconstructs the given real image. In the second part of the assignment, we will take a hand-drawn sketch and generate an image that fits the sketch accordingly. Finally, we will generate images based on an input image and a prompt using stable diffusion.
Part 1: Inverting the Generator
In this part of the assignment, I will reconstruct images from latent codes using a trained generator, by solving a non-convex optimization problem.
Loss Experiments
We fix the generator and latent space and perform some loss experiments. I use the StyleGAN generator and the W+ latent space. For L1 + L2 Loss, I add the two losses together with no weighting, but for Perceptual + L1 Loss, I have a weight of 0.01 for perceptual and weight of 10 for the L1 loss, as these are the parameters that give me the best results for each. Below are the results:
Iter = 250
Iter = 500
Iter = 750
Iter = 1000
Source Image
L1 Loss





L2 Loss




L1 + L2 Loss




Perceptual Loss




Perceptual + L1 Loss




We see that the Lp losses give us worse results than the results from the perceptual losses, with the L1 loss being slightly better than the L2 loss in capturing structure (see cat's fur at the bottom right of the image), and the L2 loss being slightly better than the L1 loss in capturing color (see purple flower in background). This is because the Lp losses do not encode as much meaningful semantic information, and just nudges the model to produce an output that is as close as possible in pixel values to the source image. On the other hand, perceptual loss manages to give semantic guidance, and the final output looks much more cat-like and accurate, with the eyes and mouth formed properly. However, because the generator was trained on cat faces, it doesn't do such a great job on reconstructing the purple flower in the background, merging it as part of the ear, and it also neglects the overall color/contrast of the image, giving something that is darker. Hence, the best result was obtained by combining both Perceptual and L1 loss (bottom row), with weights of 0.1 and 10.0 respectively, where the output just looks like a slightly blurred/distorted version of the source image.
In terms of speed, the Lp losses generate the images the fastest, while perceptual loss takes a while longer due to the need to feed the target/source images through another network. The best result's method utilizes perceptual loss, thus it takes a while longer.
Generative Model Experiments
Below are some example outputs of my image reconstruction efforts using different generative models including vanilla GAN, StyleGAN. I use the z-space latent codes as vanilla GAN does not have the w/w+ space, and I only show the output after 1000 iterations as all iterations look very similar.
Source Image
Vanilla GAN
StyleGAN



We can see that StyleGAN performs much better than vanilla GAN. The vanilla GAN output does not have eyes and a nose, and is very blurry in general. This is because StyleGAN has a much more advanced architecture that models the manifold of natural images better than vanilla GAN.
Latent Space Experiments
Below are some example outputs of my image reconstruction efforts using different latent spaces for StyleGAN. I use only StyleGAN as the vanilla GAN does not have the w/w+ space.
Iter = 250
Iter = 500
Iter = 750
Iter = 1000
Source Image
Z Space



W Space




W+ Space




As can be seen, the W+ space gives the best results, with the final output having more well-defined details, for example the cat's ears or the green background. This is because W+ is an extended latent space that has the capacity to encode more information than the more limited W space (which has several times less parameters), and thus we can fit better to the image data. Both W and W+ spaces give better results than the Z space, since the W/W+ spaces have semantically meaningful priors, compared to just the Z space which is just random noise.
Conclusion
The best results are obtained by using StyleGAN with the W+ latent space, and a combination of Perceptual and L1 loss as the loss function. I will be using these settings in Part 2.
Part 2: Scribble to Image
Next, we would like to constrain our image in some way while having it look realistic. In this assignment, we would like GAN to fill in the details given a user color scribble.
Style-space Experiments
Here are some sparser sketches:
Iter = 250
Iter = 500
Iter = 750
Iter = 1000
Source Image















Here are some denser sketches:
Iter = 250
Iter = 500
Iter = 750
Iter = 1000
Source Image
















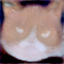





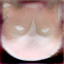
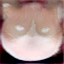






As we can see, we usually start off with a pretty realistic looking cat at 250 iterations, then it slowly becomes more and more like the scribble, and starts to look quite cartoony. This is partially because we are using the W+ latent space, so overfitting to the scribble happens more often. The sparser scribbles also preserve more realistic cat-like features as the number of iterations increase (you can see unnatural shapes that the cat images have been forced into for the denser scribbles), because the scribbles only guide their specific parts of the image (due to the mask). On the other hand, the denser scribbles start out at 250 iterations with more consistent/better looking cat images, since the scribbles tend to make the model emphasize the parts which are filled in, so basically the dense scribbles allow the model to emphasize most of the image as a whole, while the sparse scribbles only emphasize some parts, resulting in an unbalanced image.
Part 3: Stable Diffusion
In this part, I extend SDEdit with a text-to-image Diffusion model. I use the DDPM sampling method with Classifier-free Diffusion Guidance.
Guided Image Synthesis Outputs
Below are example outputs of the guided image synthesis on 2 different input images. I used the prompt "Grumpy cat reimagined as a royal painting" and "Orange cat reimagined as a royal painting" respectively, with a strength of 15, and ran for 700 timesteps.
Sketch
Synthesized




Guidance Strength Experiments
I then experiment with different classifier-free guidance strength values, and obtain these images:
Sketch
Strength = 5
Strength = 10
Strength = 15




As the guidance strength increases, we obtain images that align more with the prompt. The images on the left with guidance strength = 5 don't exactly look like royal paintings, with the first cat becoming a disembodied cat head painting, and the second cat becoming a floral print painting. On the other hand, the right-most images look more like royal paintings. We may also experience a loss of fidelity to the original sketch due to the sketch being coerced into the prompt's guidance — for example, we see in the top right image that the long pointy ears in the sketch become part of the crown instead.
Noise Experiments (Timesteps)
I liked the strength 5 images, so I used them for the rest of my experiments. Keeping everything else constant and increasing the number of timesteps to 800, I got the following outputs:
Sketch
700 timesteps
800 timesteps


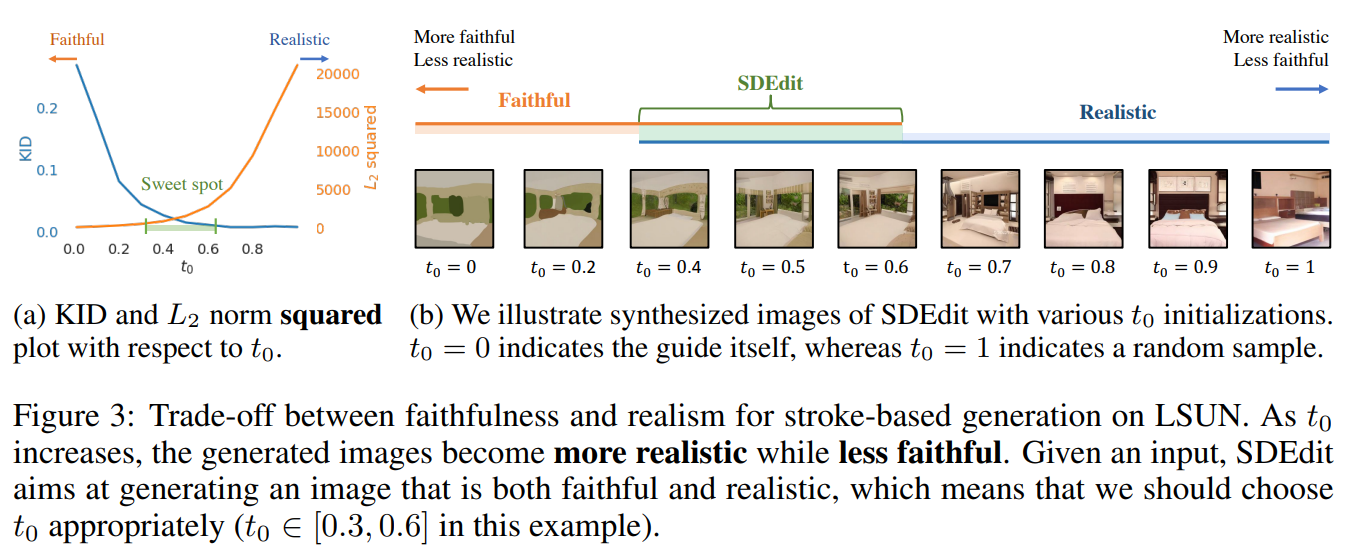
As seen in the SDEdit paper (see image below), as we increase the amount of noise by increasing the number of timesteps, our synthesized image becomes less faithful and more realistic. For example, in our images, as the number of timesteps increase, the eyes of both cats become more real-looking, and the shape of the face/ears of the cats become less similar to the sketch.
Noise Experiments (Seed)
Keeping everything else constant and changing the random seed, I got the below outputs. As expected, they are very different due to the randomly initialized noise matrices being very different.
Sketch
Seed = 10
Seed = 420


Bells and Whistles
Latent Code Interpolation
I interpolate between two latent codes in the GAN model, and generate the following image sequences:

